

استخدام التعلُّم FedML للتغلب على عيوب توسيع نطاق الذكاء الاصطناعي
نهج جديد واعد لتدريب نمذجات الذكاء الاصطناعي يُمكِّن الشركات التي لديها مجموعات بيانات صغيرة من التعاون مع حماية المعلومات المحمية بالملكية الفكرية.

الثروات الكبيرة، والوصول إلى المواهب، والاستثمارات الضخمة في البنية التحتية للحوسبة تفسر جزئياً فقط لماذا جاءت معظم الاختراقات الكبرى في الذكاء الاصطناعي من مجموعة مختارة من شركات التكنولوجيا الكبرى التي تشمل أمازون Amazon وغوغل Google ومايكروسوفت Microsoft. ما يميز عمالقة التكنولوجيا عن عديد من الشركات الأخرى التي تسعى إلى الحصول على ميزة من الذكاء الاصطناعي هو الكميات الهائلة من البيانات التي تجمعها كمشغلة للمنصات. تعالج أمازون وحدها ملايين المعاملات كل شهر على منصتها. هذه البيانات الضخمة كلها هي مورد استراتيجي غني يمكن استخدامه لتطوير خوارزميات تعلم الآلة المعقدة وتدريبها – لكنه مورد بعيد المنال بالنسبة إلى معظم المؤسسات.
يسمح الوصول إلى البيانات الضخمة بنمذجات الذكاء الاصطناعي وتعلم الآلة الأكثر تطوراً والأفضل أداء، لكن يجب على عديد من الشركات الاكتفاء بمجموعات بيانات أصغر بكثير. بالنسبة إلى الشركات الصغيرة وتلك العاملة في القطاعات التقليدية مثل الرعاية الصحية أو التصنيع أو البناء، يكون نقص البيانات أكبر عائق أمام المغامرة في الذكاء الاصطناعي. وتُعَد الفجوة الرقمية بين مؤسسات البيانات الكبيرة والصغيرة مصدر قلق كبيراً بسبب تأثيرات شبكة البيانات الذاتية التعزيز، حيث يؤدي مزيد من البيانات إلى أدوات ذكاء اصطناعي أفضل، ما يساعد على جذب مزيد من العملاء الذين يولِّدون مزيداً من البيانات، وما إلى ذلك.1S.S. Levine and D. Jain, “How Network Effects Make AI Smarter,” Harvard Business Review, March 14, 2023, https://hbr.org. وهذا يمنح الشركات الكبرى ميزة تنافسية قوية من حيث الذكاء الاصطناعي، إذ تكافح المؤسسات الصغيرة والمتوسطة الحجم لمواكبة ذلك.
كانت فكرة اضطلاع عديد من الشركات الصغيرة بتجميع بياناتها في مستودع مركزي خاضع للسيطرة المشتركة موجودة منذ فترة، لكن المخاوف بشأن خصوصية البيانات قد تقضي على مثل هذه المبادرات.2Y. Bammens and P. Hünermund, “How Midsize Companies Can Compete in AI,” Harvard Business Review, Sept. 6, 2021, https://hbr.org. تعلُّم الآلة الموحد Federated machine learning (اختصاراً: التعلُّم FedML) هو تكنولوجيا مبتكرة حديثة تتغلب على هذه المشكلة عن طريق الذكاء الاصطناعي التعاوني الذي يحافظ على الخصوصية ويستخدم البيانات اللامركزية. قد يتحول التعلم FedML إلى نهج محوري في معالجة الفجوة الرقمية بين الشركات التي لديها بيانات ضخمة وما دونها، وتمكين جزء أكبر من الاقتصاد من جني فوائد الذكاء الاصطناعي. إنه تكنولوجيا لا تبدو واعدة من الناحية النظرية فحسب – بل مطبَّقة بالفعل بنجاح في الصناعة، كما سنفصِّل أدناه. لكننا سنشرح، أولاً، كيف تعمل.
البيانات الصغيرة والتعلُّم FedML
التعلم FedML هو نهج يسمح لمؤسسات البيانات الصغيرة بتدريب نمذجات تعلُّم الآلة المتطورة واستخدامها. يعتمد تعريف البيانات الصغيرة Small data على مدى تعقيد المشكلة التي يعالجها الذكاء الاصطناعي. في مجال الأدوية، مثلاً، يُعَد الوصول إلى مليون جزيء محدَّد لاكتشاف الأدوية صغيراً نسبياً نظراً إلى المساحة الكيميائية الشاسعة. تشمل العوامل الأخرى التي تجب مراعاتها تطورَ تقنية تعلم الآلة، بدءاً من تحليل الانحدار اللوجستي Logistic regression البسيط إلى شبكة عصبية Nueral network أكثر تعطشاً للبيانات، إضافةً إلى الدقة اللازمة للتطبيق: بالنسبة إلى بعض تطبيقات الذكاء الاصطناعي (مثل إجراء تشخيص طبي)، فإن تصحيح الأمور هو ببساطة أكثر أهمية من غيره (مثل اقتراح الرموز التعبيرية عندما يكتب شخص ما). مع تساوي كل المعطيات الأخرى تواجه المؤسسات الأصغر وتلك العاملة في القطاعات التقليدية غير الرقمية عيوباً أكثر خطورة في النطاق المتعلق بالبيانات.
وقد طوِّرت بالفعل بعض التكتيكات والتقنيات المفيدة لمساعدة الشركات التي تعاني هذه المشكلة، مثل تجميع البيانات بين الشركات Cross-firm data pooling، والتعلم بالنقل transfer learning (إعادة توظيف النمذجات المدربة سابقاً)، والتعلم تحت الإشراف الذاتي Self-supervised learning (تدريب نمذجة على مجموعة بيانات اصطناعية).3R. Ramakrishnan, “How to Build Good AI Solutions When Data Is Scarce,” MIT Sloan Management Review 64, no. 2 (winter 2023): 48-53. ومع ذلك قد لا يكون النهج المركزي لتجميع البيانات مناسباً في عديد من الحالات، كما عندما تكون هناك قيود قانونية تحظر نقل البيانات أو المخاوف الاستراتيجية المتعلقة بالبيانات الحساسة التي ينبغي أن تبقى خاصة. وبالمثل فإن تكتيك نقل التعلُّم Transfer learning والتعلم الخاضع للإشراف الذاتي هما نهجان قابلان للتطبيق فقط عندما تتمكن الشركة من البناء على تبصرات سابقة من نمذجات تعلم الآلة التي تؤدي المهام في المجالات ذات الصلة، والتي قد لا تكون ممكنة دائماً. يمكن أن يكون التعلم FedML أداة إضافية قوية في مجموعة أدوات الذكاء الاصطناعي لشركة البيانات الصغيرة، ويعمل بوصفه مكملاً مُهماً لتقنيات البيانات الصغيرة الأخرى.
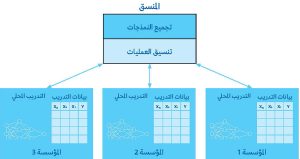
في إعداد التعلم الموحد، تُدرَّب نمذجة تعلُّم الآلة على خوادم لامركزية متعددة Multiple decentralized servers تتحكم فيها مؤسسات مختلفة، ولكل منها بياناتها المحلية Local data الخاصة. تتواصل Communicate مع منسق مركزي Central orchestrator يجمع تحديثات النمذجة الفرد وينسِّق عملية التدريب. (انظر: نظرة عامة على التعلم FedML، الصفحة 56). في أبسط الحالات، سيكون الهدف التعليمي Learning objective هو الحصول على حقائق وصفية أساسية Basic descriptive facts لتوزيع البيانات ata distribution D، مثل المتوسطات Means أو التباينات Variances. يمكن لكل شركة، مثلاً، حساب متوسط معدل الفشل لعملية تصنيع معينة في أحد مصانعها وتقديمه إلى المنسق، الذي سيجمع بعد ذلك تلك المساهمات الفردية لتشكيل تقدير مشترك أكثر دقة.
التعلم FedML هو تقنية تعلم آلي موزعة يمكن استخدامها لمجموعة متنوعة من الخوارزميات. مثلاً يمكن حساب متوسط الأوزان أو التدرجات للشبكة العصبية عبْر المؤسسات بطريقة مماثلة. المنسق مسؤول عن إعداد بنية النمذجة الأولية وتنسيق عملية التدريب، والتي تجري عادة على تكرارات متعددة Multiple iterations. ونتيجة لذلك يمكن للشركات تدريب نمذجات تعلم الآلة المعقدة مع عدد كبير من المقاييس Parameters التي قد لا تكون في متناولها، بالنظر إلى أن قيود بياناتها المحلية ستؤدي إلى دقة نمذجة دون المستوى الأمثل Suboptimal model accuracy.
الأهم من ذلك أنه تظل بيانات الشركة الأولية محفوظة، فقط البيانات الإحصائية – مثل الأوزان المقدرة Estimated weights والمقاييس الأخرى – هي التي تتشاركها مع غيرها، وتجمع مع غيرها من البيانات عند تطبيق التعلم FedML. وبهذه الطريقة يمكن لـ10 شركات بيانات صغيرة متعاونة الوصول إلى نقاط بيانات (س) تحقيقُ قوة توقعية مماثلة تقريباً مع تطبيقات تعلم الذكاء الاصطناعي/تعلم الآلة الخاصة بها كشركة واحدة أكبر بكثير مع إمكان الوصول إلى 10 أضعاف نقاط البيانات (س)، من دون المساس بخصوصية البيانات.
عند إعداد التعلم الموحد FedML، تتدرب نمذجة تعلم الآلة على خوادم لامركزية متعددة تتحكم فيها مؤسسات مختلفة، ولكل منها بياناتها المحلية الخاصة. وتتواصل مع منسق مركزي يضطلع بتجميع تحديثات النمذجة الفردية وتنسيق عملية التدريب.
التعلم FedML في القطاع الصيدلاني
الابتكار في مجال الأدوية مكلف جداً ويستغرق وقتاً طويلاً. يبلغ متوسط تكلفة طرح دواء جديد في السوق نحو 2.3 بليون دولار اعتباراً من العام 2022، وقد تستغرق العملية أكثر من 10 سنوات. تتضمن إحدى الصعوبات الرئيسة في اكتشاف الأدوية العدد الكبير جداً من الجزيئات المحتملة (ما يصل إلى 1060) والتحدي المرتبط به المتمثل في العثور على جزيئات ذات صفات واعدة في هذا الفضاء الكيميائي الشاسع. على خلفية هذه التكاليف الباهظة والعدد الهائل من الاحتمالات الجزيئية، تُعَد نمذجات تعلم الآلة التوقعية العالية الأداء حجر الزاوية في أجندة اكتشاف الأدوية التي يدفعها الذكاء الاصطناعي. تواجه شركات الأدوية أيضاً ضغوطاً حيث تستخدم الأطراف المعنية التكنولوجية الكبرى مثل ألفابت Alphabet خبراتها العميقة في الذكاء الاصطناعي وتعلم الآلة للمغامرة في اكتشاف الأدوية.
مدركاً للإحجام عن مشاركة بيانات اكتشاف الأدوية، لكن أيضاً للإمكانات الكبيرة للذكاء الاصطناعي التعاونية لتعزيز الكفاءة في اكتشاف الأدوية، بدأ هوغو سيوليمانس Hugo Ceulemans، المدير العلمي Scientific director في يانسن فارماسيوتيكا Janssen Pharmaceutica، في طرح فكرة التعلم FedML وبَدء محادثات مع أقرانه في العام 2016 تقريباً. ساهمت جهوده في النهاية في تشكيل ائتلاف ميلودي Melloddy consortium من قِبل 10 شركات أدوية في العام 2019. في منشور على مدونة Blog أشار سيوليمانس إلى أن شركات الأدوية جمعت البيانات في السابق لدعم الجهود التوقعية Predictive efforts، إلا أن نطاق التعاون كان محدوداً، نظراً إلى أن البيانات هي أصل تنافسي مكلف.4H. Ceulemans, “Melloddy: A Bold Idea Implemented,” July 28, 2020, Melloddy (blog), www.melloddy.eu. ولأن ائتلاف التعلُّم FedML الجديد سيسمح لمساهمات البيانات الأساسية بالبقاء تحت سيطرة مالكي البيانات الخام المعنيين وعدم مشاركتها، شرح قائلاً إنه من الممكن الآن نشوء نطاق أكثر طموحاً.
كان المصطلح ائتلاف ميلودي هو اختصار دفاتر الأستاذ لتعلم الآلة لاكتشاف الأدوية Machine learning ledger orchestration for drug discovery، مشروعاً تجريبياً مدته ثلاث سنوات يهدف إلى اختبار التعلم FedML من حيث الجدوى والفاعلية. وشارك في تمويل المشروع الاتحادُ الأوروبي European Union؛ ورأت المفوضية الأوروبية European Commission أن ميلودي حالة اختبار صالحة لتوليد تبصرات تنطبق حتى على قطاعات الأعمال خارج مجال الأدوية. وشملت الشركات المشاركة أسترازينيكا AstraZeneca وباير Bayer وغلاكسو سميث كلاين GSK ويانسن فارماسيوتيكا وميرك Merck ونوفارتيس Novartis وغيرها. ودعم هذه الشركاتِ شركاءُ تكنولوجيون وأكاديميون، بما في ذلك أوكين Owkin (مشروع استثماري Venture بالذكاء الاصطناعي للتكنولوجيا الحيوية) وجامعة كاي يو لوفين KU Leuven (جامعة ذات خبرة في اكتشاف الأدوية بالذكاء الاصطناعي).
من خلال استفادة بعضها من بيانات البعض الآخر، من دون مشاركتها فعلياً، أمكن لشركات الأدوية المشاركة في ميلودي تدريب نمذجات تعلُّم الآلة الخاصة بها على أكبر مجموعة بيانات لاكتشاف الأدوية في العالم، مما مكن من إجراء توقعات أكثر دقة حول الجزيئات الواعدة وتعزيز الكفاءة في عملية اكتشاف الأدوية. في منشور مدونة، أوضح ماتيو غالتييه Matheiu Galtier، المدير التنفيذي للمنتجات Chief product officer في أوكين، أنه بفضل استخدام ميلودي للتعلم الموحد، لم تغادر البيانات البنية التحتية لأي شريك من الشركات الصيدلانية. حدثت عملية تعلم الآلة محلياً في كل شركة أدوية مشاركة، وجرت مشاركة النمذجات فقط. وهكذا ”يُكرَّس جهد بحثي مهم لضمان مشاركة المعلومات الإحصائية فقط بين الشركاء“، وفق ما كتب.5M. Galtier, “Melloddy: A ‘Co-Opetitive’ Platform for Machine Learning Across Companies Powered by Owkin Technology,” Feb. 17, 2020, Melloddy (blog), www.melloddy.eu.
كشفت نتائج مشروع ميلودي التجريبي، الذي انتهى في العام 2022، أن إنشاء منصة آمنة متعددة الأطراف للتعاون بالذكاء الاصطناعي باستخدام البيانات اللامركزية أمر ممكن، وأن أداء نمذجات تعلم الآلة قد تحقق تحسينه بالفعل باستخدام نهج التعلم FedML.
الاعتبارات الاستراتيجية لائتلافات التعلم FedML
عند إنشاء ائتلاف لتعلم الآلة الموحد، يجب على المشاركين في عملية التخطيط التفكير بعناية في النهج الأمثل لتنظيم التكنولوجيا وتحفيز الشركاء. يتولى المنسق المختار دوراً محورياً في الإدارة الفاعلة لعملية التعلم FedML. يتردد قادة مؤسسات البيانات الصغيرة في بعض الأحيان في التعاون مع شركات التكنولوجيا الكبرى Big Tech companies لأنهم يستطيعون الحفاظ على سيطرة استراتيجية أكبر وبناء علاقات أوثق مع شركاء التكنولوجيا الأصغر الذين يعملون على قدم المساواة. ويخشى البعض حتى من أن شركات التكنولوجيا الكبرى ستنتقل هي نفسها إلى قطاع الشركات الأخرى، كما يحدث في مجال الأدوية.
في حالة ميلودي اختارت شركات الأدوية أوكين، وهي شركة ناشئة Startup، لتحمل مسؤولية تنظيم منصة التعلم FedML التابعة للائتلاف. قد يكون هذا نهجاً جيداً لعديد من مبادرات التعلم FedML، لكنه قد يكون محفوفاً بالمخاطر، نظراً إلى ارتفاع معدل فشل الشركات الناشئة: قد ينهار الائتلاف إذا فشلت الشركة الناشئة. هناك أيضاً خطر محتمل من أن الشركة الناشئة قد تحصل على تمويل من منافس لا يشارك في الائتلاف. إنه موقف محرج، لكنه ليس مستبعداً. لذلك إذا جرى اختيار مشروع ناشئ كمنسق رئيس للتكنولوجيا، تعيَّن على شركاء الائتلاف النظرُ بجدية في خيار رأس المال الاستثماري المؤسسي Corporate venture capital (اختصاراً: رأس المال CVC).6Y. Bammens and J. Lilienweiss, “How Tech Startups Protect Against the Downside of Corporate Venture Capital,” Entrepreneur & Innovation Exchange, Dec. 2, 2022, https://eiexchange.com. عندما تكون للشركاء حصة مشتركة كبيرة في رأس المال المؤسسي في الشركة الناشئة، مع حق الشُفعة Rights of first refusal، تكون لديهم سيطرة أقوى بكثير على طول طريق الشركة الناشئة في مجال التكنولوجيا ومسارها المستقبلي.
يمكن أن يؤدي التعلم FedML إلى مشكلة حوافز Incentive problem، حيث يفشل بعض المشاركين في استخدام البيانات المحلية ذات الصلة كلها، أو يهملون الاستثمار في البنية التحتية للبيانات اللازمة لتحسين دقة نمذجاتهم المحلية. قد يختارون عدم بذل الجهد مع الاعتماد على مساهمات البيانات التي يقدمها شركاء الائتلاف الآخرون. ثم يقوض سلوك استغلال جهود المجموع Free-riding behavior هذه الدوافعَ والمشاركة لدى المشاركين ذوي النيات الحسنة. لاستباق هذه المشكلة يمكن لائتلاف التعلم FedML الاتفاق على التزامات الشركاء المناسبة من حيث الكمية والتغطية فيما يخص البيانات المساهمة وتحديدها مقدماً في اتفاقية تعاقدية. يمكن أيضاً مراقبة تحديثات النمذجة المحلية من قِبل المنسق من حيث مساهمتها في الدقة الإجمالية للنمذجة المشتركة، ويمكن جعل دفع رسوم خدمة التعلم FedML متناسباً مع مساهمة كل شريك في عملية FedML.
عند اتخاذ الخطوات الأولى نحو تجميع ائتلاف التعلم FedML، يكون تأمين مشاركة الشركاء أمراً حيوياً. لذلك يجب إشراك الشركاء في تحديد أهداف الائتلاف في مقابل التزاماتهم المتعلقة بالبيانات. تُعد إيه آي كانفاس AI Canvas أداة لاتخاذ القرار يمكن أن تكون مفيدة في تحديد حالات استخدام تعلُّم الآلة وبيانات التدريب المطلوبة ومناقشتها.7A. Agrawal, J. Gans, and A. Goldfarb, “A Simple Tool to Start Making Decisions With the Help of AI,” Harvard Business Review, April 17, 2018, https://hbr.org. عند الاتصال بالشركاء، ضعوا في اعتباركم أن تحديثات النمذجة الفاعلة في معظم تطبيقات التعلم FedML تتطلب الوصول إلى البيانات المحلية حول جميع متغيرات النمذجة ذات الصلة. نتيجة لذلك كثيراً ما ستعثرون على شركاء مناسبين في الصناعة نفسها، ومشاركة العمليات والبيانات التجارية المماثلة. قد يكون العمل مع المنافسين غير المباشرين، مثل أولئك الذين يخدمون أسواقاً جغرافية أخرى، بدلاً من المنافسين المباشرين مفيداً هنا لتقليل النزاعات المحتملة. بالنسبة إلى مؤسسات البيانات الصغيرة التي تغامر في التعلم FedML، ينصح بالبَدء بمشروعات تعلم الآلة القابلة للتحقيق لتأسيس الزخْم وبناء الثقة بين الشركاء قبل الشروع في مشروعات أكثر طموحاً.
لا يزال التعلُّم FedML نهجاً جديداً في الذكاء الاصطناعي، حدث تطويره في العام 2016 من قِبل مجموعة من مهندسي غوغل Google.8H.B. McMahan, E. Moore, D. Ramage, et al., “Communication-Efficient Learning of Deep Networks From Decentralized Data,” Proceedings of the 20th International Conference on Artificial Intelligence and Statistics 54 (April 2017): 1273-1282. لكن التقدم في هذا المجال يسير بخطى سريعة، ويمكننا أن نتوقع زيادة في اعتماده في مجموعة من قطاعات الأعمال. إن قادة التفكير المستقبلي لمؤسسات البيانات الصغيرة الذين يدمجون التعلم FedML في رؤاهم الاستراتيجية هم في وضع أفضل لتسخير القوة التحويلية الذكاء الاصطناعي من أجل تشكيل نجاحهم في المستقبل.
المراجع
| ↑1 | S.S. Levine and D. Jain, “How Network Effects Make AI Smarter,” Harvard Business Review, March 14, 2023, https://hbr.org. |
|---|---|
| ↑2 | Y. Bammens and P. Hünermund, “How Midsize Companies Can Compete in AI,” Harvard Business Review, Sept. 6, 2021, https://hbr.org. |
| ↑3 | R. Ramakrishnan, “How to Build Good AI Solutions When Data Is Scarce,” MIT Sloan Management Review 64, no. 2 (winter 2023): 48-53. |
| ↑4 | H. Ceulemans, “Melloddy: A Bold Idea Implemented,” July 28, 2020, Melloddy (blog), www.melloddy.eu. |
| ↑5 | M. Galtier, “Melloddy: A ‘Co-Opetitive’ Platform for Machine Learning Across Companies Powered by Owkin Technology,” Feb. 17, 2020, Melloddy (blog), www.melloddy.eu. |
| ↑6 | Y. Bammens and J. Lilienweiss, “How Tech Startups Protect Against the Downside of Corporate Venture Capital,” Entrepreneur & Innovation Exchange, Dec. 2, 2022, https://eiexchange.com. |
| ↑7 | A. Agrawal, J. Gans, and A. Goldfarb, “A Simple Tool to Start Making Decisions With the Help of AI,” Harvard Business Review, April 17, 2018, https://hbr.org. |
| ↑8 | H.B. McMahan, E. Moore, D. Ramage, et al., “Communication-Efficient Learning of Deep Networks From Decentralized Data,” Proceedings of the 20th International Conference on Artificial Intelligence and Statistics 54 (April 2017): 1273-1282. |





