

كيفية بناء حلول ذكاء اصطناعي جيدة عندما تكون البيانات شحيحة
يتواتر نشوءُ تقنيات الذكاء الاصطناعي الموفرة للبيانات – وهذا يعني أنكم لا تحتاجون دائماً إلى كميات كبيرة من البيانات المصنَّفة لتدريب أنظمة الذكاء الاصطناعي المستندة إلى الشبكات العصبية.

تُفيد قواعد الحكمة التقليدية بأنكم تحتاجون إلى كميات كبيرة من بيانات التدريب المصنفة Labeled training data لإطلاق العنان للقيمة من نماذج الذكاء الاصطناعي AI models القوية. بالنسبة إلى شركات الإنترنت الاستهلاكية حيث نشأت عديد من نماذج الذكاء الاصطناعي الحالية، لم يكن من الصعب الحصول عليها. لكن بالنسبة إلى الشركات في القطاعات الأخرى – مثل الشركات الصناعية وشركات التصنيع ومؤسسات الرعاية الصحية والمؤسسات التعليمية – يمكن أن يكون تنسيق البيانات المصنفة بكميات كافية أكثر صعوبة بقدر كبير.
ومع ذلك هناك أخبار سارة على هذه الجبهة. على مدى السنوات القليلة الماضية، طور الممارسون والباحثون في الذكاء الاصطناعي عدة تقنيات لتقليل حجم البيانات المصنفة اللازمة لبناء نماذج دقيقة للذكاء الاصطناعي. باستخدام هذه الأساليب، في الأغلب يكون من الممكن بناء نموذج (نمذجة) جيد للذكاء الاصطناعي بجزء صغير من البيانات المصنفة التي قد تكون مطلوبة بخلاف ذلك.
يُعَد تجميع كثير من البيانات المصنفة أمراً مكلفاً وصعباً. تخيلوا أنكم الرئيس التنفيذي CEO لشركة لتصنيع أثاث المكاتب المنزلية. ينشر عملاؤكم مراجعات Reviews لمنتجاتكم على مواقع التجارة الإلكترونية ووسائل التواصل الاجتماعي، وتوفر بعض هذه المراجعات رؤى عميقة (تبصرات) قيمة حول عيوب المنتجات والتحسينات المحتملة.
ونظراً إلى نمو أعمالكم نمواً سريعاً، نما أيضاً حجم محتوى المراجعة إلى مستوى تستحيل معه قراءة كل قطعة يدوياً واستخلاص إمكانياتها لتحسين المنتجات. تقررون أنكم في حاجة إلى بناء نموذج ذكاء اصطناعي يمكنه ”قراءة“ كل مراجعة وتقييم ما إذا كانت تحتوي على عيب أو فكرة تحسين أو لا شيء. مع وجود نموذج كهذا، يمكنكم توجيه المراجعات ذات الصلة إلى الفرق المناسبة للمتابعة.
يتكون النهج التقليدي للذكاء الاصطناعي لحل هذه المشكلة من الخطوات التالية: (1) تجميع مجموعة بيانات من المراجعات، و(2) تصميم عملية لتصنيف كل مراجعة بكلمة ”تحسين“ أو ”عيب“ أو ”لا شيء“، و(3) تعيين فريق من المصنفين وتدريبهم على تصنيف البيانات بدقة، و(4) تصنيف الآلاف (إن لم يكن عشرات الآلاف) من المراجعات، و(5) باستخدام مجموعة بيانات المراجعة والتصنيف هذه، بناء سلسلة من نماذج الذكاء الاصطناعي عبر عمليات التجربة والخطأ حتى تصلوا إلى نموذج يمكنه تصنيف المراجعات بدقة مقبولة.
قد تكون الخطوتان 3 و4 أكثر صعوبة وتكلفة مما قد يبدو. على عكس النظر إلى صورة وتحديد ما إذا كانت كلباً أو قطة، قد يكون تحديد ما إذا كانت المراجعة تضم فكرة لتحسين المنتج أمراً صعباً جداً. قد يختلف المصنفون المختلفون حول التصنيف الصحيح لمراجعة ما، وستحتاجون إلى آلية للفصل في الخلافات.1M. Bernstein, “Labeling and Crowdsourcing,” Data-Centric AI, accessed June 13, 2022, https://datacentricai.org.
وقد تكون هذه المسائل أسوأ في سياقات معينة حيث قد يكون من المستحيل الحصول على تصنيفات إضافية حتى إذا كنتم على استعداد لاستثمار الوقت ورأس المال. في الرعاية الصحية: خذْ مثلاً الموت القلبي المفاجئ Sudden cardiac death (اختصاراً: الموت SCD). عادةً ما تحتوي مجموعات البيانات القياسية التي تشمل ملايين من سجلات المرضى على عدد صغير فقط من السجلات ”المُصنَّفة“ على أنها حالات موت قلبي مفاجئ. مع هذا العدد الصغير من الأمثلة المصنفة، قد لا يكون من الممكن بناء نموذج دقيق لتوقُّع مخاطر الموت القلبي المفاجئ على أساس المتغيرات الأخرى. ولا يمكننا اختيار زيادة عدد الأمثلة المصنفة أيضاً، إذا كان انتشار الموت القلبي المفاجئ منخفضاً جداً بين المرضى أصلا.2N. Diamant, E. Reinertsen, S. Song, et al., “Patient Contrastive Learning: A Performant, Expressive, and Practical Approach to Electrocardiogram Modeling,” PLOS Computational Biology 18, no. 2 (Feb. 14, 2022): 1-16. لنأخذ مثالاً آخر، إذا أردنا بناء نظام ذكاء اصطناعي لاكتشاف العيوب في الهواتف الصادرة من خط التصنيع، فسنواجه مشكلة مماثلة إذا كان المصنع قد صنع 50 هاتفاً مَعيباً فقط.3S. Brown, “Why It’s Time for ‘Data-Centric Artificial Intelligence,’ ” MIT Sloan School of Management, June 7, 2022, https://mitsloan.mit.edu.
تتيح الأساليب الجديدة لمطوري الذكاء الاصطناعي نقلَ النماذج عبر المشكلات ذات الصلة ونماذج الاختبار المسبق ببيانات غير مصنفة.
في ظل هذه الخلفية، أدرك الممارسون والباحثون قيمة تقنيات تقليل عدد الأمثلة المصنفة اللازمة لبناء نماذج دقيقة وصمموا تقنيات كهذه. تشمل هذه الأساليب طرقاً لنقل النماذج عبر المشكلات ذات الصلة وللتدريب المسبق على النماذج باستخدام البيانات غير المصنفة. وهي تشمل أيضاً أفضل الممارسات الناشئة حول الذكاء الاصطناعي المتمحور حول البيانات، والتي نناقشها أدناه.
تُظهر هذه المنهجيات وعداً كبيراً. مثلاً، باستخدام إحدى هذه التقنيات، تمكن الباحثون في معهد برود Broad Institute (المرتبط بمعهد ماساتشوستس للتكنولوجيا MIT، وهارفارد Harvard، ومستشفى ماساتشوستس العام Massachusetts General Hospital) من بناء نموذج لتوقع خطر الإصابة بالرجفان الأذيني Atrial fibrillation بنحو 6% فقط من الأمثلة المصنفة التي كانت الحاجة ستدعو إليها لبناء نموذج جيد بالقدر نفسه من الصفر.
لفهم كيفية عمل هذه التقنيات، دعونا نفحصْ ما يحدث داخل شبكة عصبية Neural network – تعتمد عليها الأغلبية العظمى من حلول الذكاء الاصطناعي – عند تدريبها على حل مشكلة التوقع.
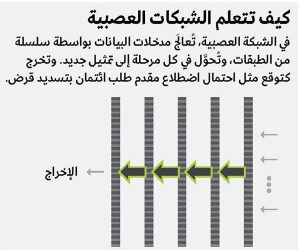 الشبكات العصبية تتعلم التمثيل
الشبكات العصبية تتعلم التمثيل
تتكون الشبكات العصبية عادةً من طبقات مرتبة في تسلسل: طبقة إدخال Input layer، وطبقات متعددة يجري فيها تحويل البيانات، وطبقة مخرجات Output layer (انظر: ”كيف تتعلم الشبكات العصبية“). تدخل بيانات الإدخال إلى الشبكة في أحد طرفيها، وتتدفق عبر الطبقات، وتخرج من الطرف الآخر كتوقع.
عندما تتدفق البيانات عبر طبقة، يجري تحويلها. قد تدخل الطبقة الأولى، مثلاً، قائمة من 10 أرقام، وبعد سلسلة من العمليات الحسابية، تخرج كقائمة من 20 رقماً. تدخل هذه القائمة المكونة من 20 رقماً في الطبقة الثانية وقد تخرج كقائمة من خمسة أرقام، وهكذا. أخيراً ستُنتج طبقة الإخراج رقماً واحداً فقط إذا كنا نحاول توقع رقم واحد (مثل احتمال أن يسدد مقدم طلب القرض قرضه، أو احتمال أن يشير مخطط كهربية القلب إلى وجود مرض في القلب، أو القيمة المحتملة لمنزل) أو أرقام متعددة (مثل احتمال أن تشير مراجعة المنتج إلى وجود عيب/تحسين/لا شيء، أو خط العرض وخط الطول لمركبة من مركبات مشاركة الركوب Ride-sharing vehicle). تسمى هذه الإصدارات المحولة من المدخلات التي تنتجها كل طبقة من الطبقات الوسيطة التمثيلات Representations. يمكننا أيضاً التفكير في التمثيل كإصدار مشفر (مرمَّز) من المدخلات الأولية، ويمكن اعتبار الطبقات التي تنتج هذه الإصدارات المشفرة على أنها أدوات تشفير Encoders.
عند تدريب شبكة عصبية على حل مشكلة توقع معينة، ينتهي الأمر بتعلم شيئين: كيفية تحويل بيانات الإدخال أو تشفيرها (ترميزها) إلى تمثيلات جيدة، وكيفية توقع الإخراج المطلوب من هذه التمثيلات.
تبين أن هذه التمثيلات/أدوات التشفير مفيدة جداً لبناء نماذج ذكاء اصطناعي موفرة للبيانات. يمكن استخدام التمثيلات التي تعلمتها الشبكة العصبية لمشكلة واحدة في مشكلات أخرى، لأنها تلتقط الجوانب الجوهرية لنوع البيانات التي تُغذَّى بها الشبكة.
مثلاً، عند تدريب شبكة عصبية عميقة لاكتشاف ما إذا كانت الصورة تحتوي على واحدة من ألف فئة من مختلف كائنات العالم الحقيقي (مثل الأشخاص، والحيوانات، والأزهار، والأثاث، والمركبات)، يتبين أن التمثيلات التي تعلمتها الطبقة الأولى تتوافق مع ميزات بسيطة مثل الخطوط المستقيمة وتدرجات اللون؛ وترصد الطبقة الثانية الحوافَّ والزوايا والدوائر؛ وتبني الطبقة الثالثة على الطبقة السابقة لتمثيل أشكال أكثر تعقيداً (مثل قرص العسل أو مخطط جذع بشري)، وهكذا.4M.D. Zeiler and R. Fergus, “Visualizing and Understanding Convolutional Networks,” in “Computer Vision — ECCV 2014,” eds. D. Fleet, T. Pajdla, B. Schiele, et al. (Zurich: Springer, 2014), 824.
يثير هذا احتمالاً جاذباً للاهتمام: ربما يمكننا إعادة استخدام التمثيلات لحل المشكلات الأخرى التي تعتمد على النوع نفسه من بيانات الإدخال. مثلاً، هل يمكن استخدام التمثيلات من الشبكة العصبية الموصوفة أعلاه لبناء شبكة عصبية بكفاءة لأي مشكلة في تصنيف الصور حيث تكون المدخلات صوراً لأشياء يومية؟
يتبين أن الإجابة هي نعم مدوية.
إذا تمكنا من الوصول إلى شبكة مدربة على نوع بيانات الإدخال نفسه مثل تلك التي نعمل معها، يمكننا استخراج تمثيلات من هذه الشبكة وبناء نموذج بسيط مع تلك التمثيلات كمدخلات وتصنيفاتنا كمخرجات. لن نحتاج إلى بيانات مصنفة ثمينة لمعرفة التمثيل الجيد بعد الآن، نظراً إلى أننا نحصل على تمثيلات جيدة “مجاناً ”. يمكننا استخدام البيانات المصنفة لدينا كلها فقط لتعلم النموذج البسيط. ونظراً إلى أن النماذج البسيطة ليست متعطشة للبيانات مثل النماذج الأكثر تعقيداً، يمكننا على الأرجح إنجاز المهمة باستخدام عدد أقل من البيانات المصنفة.
نقل التعلم: العثور على التمثيلات وتغيير الغرض منها
تتمثل نقطة البداية الجيدة للعثور على تمثيلات مفيدة في معرفة ما إذا كانت نماذج الشبكات العصبية الأخرى قد أُنشئِت باستخدام النوع نفسه من بيانات الإدخال. بالعودة إلى مثال أثاث المكاتب المنزلية، ربما بنى فريق آخر في الشركة شبكة عصبية لتوقُّع المشاعر المعبَّر عنها في مراجعة منتج من نص المراجعة. لاحظوا أن تصنيفات المخرجات التي جرى تدريب هذه الشبكة العصبية على توقُّعها تختلف عن مشكلتكم: المشاعر الإيجابية/المشاعر السلبية/الحيادية بدلاً من التحسين/العيب/لا هذه ولا تلك.
 تغيير الغرض من الشبكات العصبية باستخدام نقل التعلم
تغيير الغرض من الشبكات العصبية باستخدام نقل التعلميمكن للمطورين استخدام شبكة عصبية أُنشِئت مسبقاً ومدربة بنوع بيانات الإدخال نفسه لكن مع تصنيفات مخرجات مختلفة كنقطة انطلاق لشبكة عصبية جديدة. يمكنهم نقل الشبكة العصبية الأصلية من خلال الطبقة الثانية إلى الأخيرة وإرفاق طبقة مخرجات جديدة ثم تدريب الشبكة الجديدة بمجموعة مختلفة من تصنيفات المخرجات.
لأداءٍ دقيق، يجب أن تكون هذه الشبكة العصبية لاكتشاف المشاعر قد تعلمت أنماطاً مفيدة موجودة في اللغة الطبيعية ونوع النص المحدد الذي يتجلى في مراجعات المنتجات. سينعكس هذا التعلم في التمثيلات الناتجة عن طبقاته عند وضع مراجعة في هذه الشبكة. على وجه الخصوص، من المرجح أن يكون التمثيل الخارج من الطبقة قبل الأخيرة تمثيلاً مفيداً للمراجعة المدخلة. (انظر: تغيير الغرض من الشبكات العصبية باستخدام نقل التعلم).
يمكن عرض الشبكة العصبية من طبقة الإدخال عبر الطبقة قبل الأخيرة على أنها أداة تشفير للمراجعات. يمكننا استخراج أداة التشفير من الشبكة العصبية، وإضافة طبقة مخرجات جديدة بها لتشكيل شبكة عصبية جديدة، وتدريب هذه الشبكة مع تصنيفات المخرجات لمشكلتنا.
عند تدريب هذه الشبكة، يمكننا فقط معرفة مقاييس طبقة المخرجات التي أضفناها (الحفاظ على مقايس أداة التشفير)، أو يمكننا تحديث المقاييس كلها. تسمى خطوة تحديث المقياس هذه الضبط الدقيق Fine-tuning، وتسمى العملية الكلية التي وصفناها نقل التعلم Transfer learning.
قد يمكِّننا نقل التعلم من بناء نماذج ذكاء اصطناعي جيدة بعدد أقل بنحو ملحوظ من البيانات المصنفة. وفي مشكلة تتعلق بتصنيف الصور إلى فئة من 10 فئات، أسفر استخراج أداة تشفير من شبكة عصبية أخرى وضبطها الدقيق على 50 مثالاً مصنَّفاً فقط عن نموذج أكثر دقة من شبكة مدربة من الصفر على 5,000 مثال.5A. Kolesnikov, L. Beyer, X. Zhai, et al., “Big Transfer (BiT): General Visual Representation Learning,” arXiv, May 5, 2020, https://arxiv.org.
التعلُّم الخاضع للإشراف الذاتي: تمثيلات التعلُّم من البيانات غير المصنَّفة
في حين أن التعلم عن طريق النقل يمكن أن يكون فاعلاً إلى أقصى حد، فإن نقطة البداية هي نموذج دُرِّب على مدخلات مماثلة. لكن ماذا لو كان هذا النموذج غير متوافر؟ هل يمكننا بناء أداة تشفير (تولد تمثيلات جيدة) بأنفسنا، باستخدام البيانات غير المصنفة فقط؟
في الواقع هذا ممكن باستخدام تقنية تسمى التعلم الخاضع للإشراف الذاتي Self-supervised. تتمثل الفكرة الرئيسة وراء التعلم الخاضع للإشراف الذاتي في إنشاء مجموعة بيانات ”اصطناعية“ Artificial من المدخلات والتصنيفات من البيانات غير المصنفة، ومن ثم تدريب نموذج الشبكة العصبية على هذه المجموعة الاصطناعية.
بينما جرب الباحثون عديداً من الأساليب لإنشاء مجموعات بيانات مُدخلات اصطناعية، فإن إحدى التقنيات الأكثر فاعلية والأكثر استخداماً هي عملية بسيطة من خطوتين بنحو مدهش.
في الخطوة الأولى نأخذ كلَّ مثال غير مصنف، ونُزيل عشوائياً عدداً صغيراً من متغيراته الفردية (بمعنى آخر، نفرغ جزءاً منه عشوائياً). ما يتبقى هو المدخلات الاصطناعية. وتصبح الأجزاء المُزالة تصنيفات اصطناعية.
لمعرفة كيف يمكن تطبيق هذا النهج على مدخلات النص، انظروا في نقطة البيانات غير المصنفة هذه: ”تتمثل مهمة كلية إم آي تي سلون للإدارة في تطوير قادة مبدعين ومبتكرين يحسِّنون العالم ويولِّدون أفكاراً تعزز ممارسة الإدارة“.
سنختار عشوائياً ثلاث كلمات من هذه الجملة للإزالة: المهمة والقادة والتوليد. تصبح هذه الكلمات تصنيفات اصطناعية، وما تبقى من الجملة الأصلية هو المدخلات الاصطناعية: ”تتمثل ____ كلية إم آي تي سلون للإدارة في تطوير ____ مبدعين ومبتكرين يحسِّنون العالم و____ أفكاراً تعزز ممارسة الإدارة“. تخيلوا الآن إجراءَ ذلك على البيانات النصية المتاحة لديكم كلها، وإنشاء الآلاف من أزواج تصنيف (تصنيفات) الإدخال.
بعد إنشاء مجموعة بيانات اصطناعية كما هو موصوف، في الخطوة الثانية نضطلع بتدريب شبكة عصبية لتوقع التصنيفات الاصطناعية من المدخلات الاصطناعية. (انظر: تدريب الشبكات العصبية بالتعلم الخاضع للإشراف الذاتي، الصفحة 52).
في عملية التعلم لتوقع العناصر المفرغة للمدخلات من العناصر المتبقية، تتعلم الشبكة العصبية كيف ترتبط هذه العناصر بعضها ببعض، ومن ثم تتعلم تمثيلاً جيداً لبيانات الإدخال. يمكن استخلاص أداة التشفير التي تولد هذه التمثيلات بسهولة من هذه الشبكة العصبية، ثم ضبطها بدقة ببيانات مصنفة ثمينة (تماماً كما هي الحال في نقل التعلم).
تعمل العملية الموضحة لإنشاء أزواج تصنيف الإدخال الاصطناعية بنحو جيد عندما تكون بيانات الإدخال عبارة عن نص بلغة طبيعية أو بيانات مهيكلة. بالنسبة إلى مدخلات الصور، عُثر على مجموعة من التقنيات لتكون فاعلة جداً: تعزيز البيانات Data augmentation، إلى جانب نهج الإشراف الذاتي المعروف باسم التعلم المتباين Contrastive learning، حيث تُدرَّب الشبكة العصبية فيكون للنسخ المعدلة قليلاً من الصورة تمثيلات متشابهة في حين لا يصح ذلك للصور المتميزة.6T. Chen, S. Kornblith, M. Norouzi, et al., “A Simple Framework for Contrastive Learning of Visual Representations,” arXiv, Feb. 13, 2020, http://arxiv.org.
يمكن أن يؤدي إنشاء أداة تشفير باستخدام التعلم الخاضع للإشراف الذاتي/التعلم المتباين Self-supervised/contrastive learning متبوعاً بخمس مراحل ضبط دقيق Fine-tuning إلى تمكين بناء نماذج جيدة للذكاء الاصطناعي ببيانات أقل تصنيفاً بنحو ملحوظ. في دراسة اشتملت على مجموعة بيانات صورية معروفة من إيماج نت ImageNet، احتاجت أداة تشفير تحتوي على صور غير مصنفة تعمل بالتعلم المتباين والضبط الدقيق لها فقط 1% فقط من الأمثلة المصنفة المتاحة عن نموذج أكثر دقة من نموذج دُرِّب على الأمثلة المصنفة كلها.7.Ibid
لقد أوصينا بعملية من خطوتين لإنشاء نماذج بعدد أقل من البيانات المصنفة: نزِّلوا أداة تشفير مُدربة مسبقاً، أو أنشِئوا أداة تشفير خاصة بكم باستخدام بيانات غير مصنفة، ثم اضبطوا أداة التشفير باستخدام بياناتكم المصنفة النادرة.
أصبح العثور على أداة تشفير مناسبة أسهلَ الآن بفضل محاور النماذج عبر الإنترنت، حيث يتيح باحثون وممارسون في الذكاء الاصطناعي نماذج ورموزاً مدرَّبة لاستخدام الشبكات العصبية.
أصبح العثور على أداة تشفير مناسبة أو إنشاء أداة تشفير خاصة بكم أسهل بقدر ملحوظ من خلال نشوء محاور النماذج Model hubs (المعروفة أيضاً باسم حدائق النماذج Model zoos). محاور النماذج هي مواقع على الإنترنت حيث يتيح باحثون وممارسون في الذكاء الاصطناعي في أنحاء العالم كلها نماذج ورموزاً مدرَّبة لاستخدام الشبكات العصبية. وهناك ثلاثة محاور نموذجية شائعة هي تنسور فلو TensorFlow وباي تورش PyTorch وهاغنغ فايس Hugging Face. من خلال الاستفادة من محاور النماذج، في الأغلب يكون من الممكن إنشاء نماذج ذكاء اصطناعي موفرة للبيانات بجهد أقل بقدر ملحوظ.
الذكاء الاصطناعي المتمحور حول البيانات: تكرار البيانات، وليس فقط النموذج
رأينا أن البدء بنموذج جرى اختباره مسبقاً يمكن أن يقلل من الحاجة إلى البيانات المصنفة. ننتقل الآن إلى مسألة ما يجب عملُه عند ضبط نموذجنا الذي جرى اختباره مسبقاً باستخدام البيانات المصنفة الثمينة لكن أداءه لا يزال غير كافٍ لتلبية احتياجاتنا.
عند مواجهة هذا الموقف، عادةً ما تضطلع فرق الذكاء الاصطناعي/تعلم الآلة بـ تكرار النموذج Iterate on the model – وهي عملية من عمليات التجربة والخطأ التي تتضمن إنشاء متغيرات إدخال جديدة من خلال الجمع بين المتغيرات الحالية (المعروفة باسم هندسة الميزات Feature engineering)، ومحاولة إجراء تعديلات مختلفة على بنية النموذج وغيرها من مقاييس التصميم، وتقييم الأداء الناتج على بيانات اختبارية.
على الرغم من أن هذه استراتيجية معقولة، فإن هناك إدراكاً متزايداً أن هياكل الشبكات العصبية الحديثة قوية بالفعل وليس هناك مجال كبير لتحسينها. قد يكون من الأكثر فاعلية الحصولُ على نموذج جيد عُمِد إلى اختباره مسبقاً (كما هو موضح سابقاً) والتكرار على البيانات بدلاً من ذلك – وهي ممارسة ناشئة تسمى الذكاء الاصطناعي المتمحور حول البيانات Data-centric AI.
تبدأ ممارسة الذكاء الاصطناعي المتمحور حول البيانات من خلال التركيز على التصنيفات غير المتسقة. في عديد من مشكلات العالم الحقيقي، قد يخضع التصنيف الصحيح لمثال للتفسير. فلنأخذْ مثالاً بسيطاً، تخيلوا أنكم تبنون نموذجاً لتصنيف صور الموز إلى ثلاث فئات: غير ناضج أو ناضج أو فاسد. نظراً إلى عدم وجود طريقة لا لبس فيها لتحديد النضج، يمكن تصنيف الصورة نفسها على أنها لموزة غير ناضجة أو ناضجة بواسطة تصنيفات مختلفة.8F. Chollet, “Deep Learning With Python,” 2nd ed. (Shelter Island, New York: Manning Publications, 2021). للحصول على مثال أكثر جدية، انظروا في تصنيف صورة للجزء الاصطناعي على أنها بها عيب أو لا. هذا يمكن أن يكون تحدياً للحالات ”المتطرفة“، وحتى المصنفون قد يختلفون حول بعض الأمثلة.9A. Ng, “MLOps: From Model-Centric to Data-Centric AI,” PDF file (Palo Alto, California: DeepLearning.AI, June 2021), www.deeplearning.ai.
تُعتبَر التصنيفات غير المتسقة مشكلةً لأن نماذج الذكاء الاصطناعي العالية المرونة الحالية قد تضطر إلى بذل مزيد لاستيعابها وفهمها ومن ثم تتسع قاعدة بيانات التدريب. نتيجة لذلك تميل نماذج كهذه إلى الأداء أداءً سيئاً عند تطبيقها في مرحلة الإنتاج. كيف يمكن التخفيف من هذا؟ يمكن أن يساعد الحصول على مزيد من البيانات المصنفة في حل هذه المسألة، نظراً إلى أن مزيداً من البيانات يمكن أن يعوض الضرر الناجم عن التصنيفات غير المتسقة. لكن قد تكون هناك حاجة إلى مزيد من الأمثلة المصنفة.
هناك خيار أفضل: إصلاح التصنيفات! يمكن أن يكون هذا أكثر فاعلية – من حيث جهة التكلفة – من جمع مزيد من البيانات المصنفة. في أحد السيناريوهات حيث كان نحو 12% من 500 مثال تدريبي يحتوي تصنيفات غير متسقة، كانت الدقة أقل من 50%. أدى إصلاح التصنيفات من دون تغيير النموذج إلى زيادة الدقة إلى 60%. لكن للوصول إلى مستوى الدقة هذا من دون إصلاح التصنيفات، كان من الضروري استخدام 1,000 مثال آخر.10Chollet, “Deep Learning With Python.”
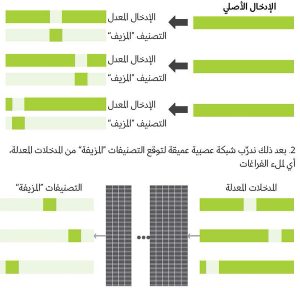 تدريب الشبكات العصبية بالتعلم الخاضع للإشراف الذاتي
تدريب الشبكات العصبية بالتعلم الخاضع للإشراف الذاتيتتمثل الخطوة الأولى للتعلم الخاضع للإشراف الذاتي في تعديل بيانات الإدخال الأصلية لإنشاء أزواج مزيفة، وذلك من خلال تحديد جزء من الإدخال العشوائي والتصنيف هذه المدخلات. في الخطوة الثانية، يجري تدريب الشبكة العصبية على توقُّع التصنيفات المزيفة من المدخلات المعدلة – أي لملء الفراغات.
1. نعمل على تعديل بيانات الإدخال الأصلية لإنشاء أزواج ”مزيفة“ (إدخال، تصنيف) عن طريق تحديد جزء من الإدخال وتصنيف هذه المدخلات
عادةً ما يؤدي إصلاح التصنيفات غير المتسقة وإعادة تدريب النموذج إلى تعزيز الأداء، لكن إذا أردنا تحسين النموذج بقدر أكبر، فسيكون من الضروري جمع مزيد من الأمثلة المصنفة. ومع ذلك يمكن تقليل عدد الأمثلة الإضافية التي يجب جمعها بالاختيار الدقيق جداً لما نختار جمعَه وتصنيفه.
عادةً لا ترتكب النماذج أخطاء بنمط موحد ومتسق عبر النطاق الكامل لبيانات الإدخال. قد تكون معدلات الخطأ الخاصة بها أعلى بكثير بالنسبة إلى مجالات معينة من بيانات الإدخال مقارنة بالمناطق الأخرى. من خلال جمع مزيد من البيانات المصنفة من مجالات الخطأ تلك بدلاً من المجالات كلها، وإعادة تدريب النموذج بهذه البيانات الإضافية، يمكن تحقيق تحسينات في أداء النموذج بنحو أكثر كفاءة.
يمكن أن يؤدي تحليل أخطاء النموذج إلى تقديم أدلة قيمة لما قد تكون عليه مجالات الخطأ. يتضمن ذلك تحديد القواسم المشتركة عبر نقاط البيانات حيث يرتكب النموذج أخطاء. مثلاً أدرك فريق الذكاء الاصطناعي الذي يعمل على نموذج التعرف على الكلام أن معدل الخطأ في النموذج كان أعلى كثيراً بالنسبة إلى إدخال الكلام حيث كانت ضوضاء السيارات موجودة. وجمع الفريقُ مزيداً من بيانات الكلام مع ضوضاء السيارات وأعاد تدريب النموذج وتحسن أداؤه.11DeepLearning.AI, “A Chat With Andrew: MLOps: From Model-Centric to Data-Centric AI,” YouTube video, 1:00:10, March 4, 2021, www.youtube.com.
وبالمثل، أدرك باحثو علم الأمراض الذين يعملون على نموذج لاكتشاف سرطان الثدي النقيلي Metastatic breast cancer أن جزءاً كبيراً من الأخطاء كان نتيجة لتصنيف إيجابي كاذب False-positive classification بناءً على تشابُه الخلايا بخلايا السرطان في المناطق السلبية الصعبة في شرائح الإدخال. من خلال توليد أمثلة إضافية من تلك المناطق، تمكنوا من تحسين النموذج.12D. Wang, A. Khosla, R. Gargeya, et al., “Deep Learning for Identifying Metastatic Breast Cancer,” arXiv, June 18, 2016, https://arxiv.org.
أبلغ الممارسون عن نتائج واعدة من تبني نهج متمحور حول البيانات. في دراسة لثلاث مشكلات نشأت في إطار اصطناعي، كان النهج المتمحور حول البيانات قادراً على تحقيق مكاسب أفضل مما يحققها النهج المتمحور حول النماذج البحت.13Chollet, “Deep Learning With Python.”
فائدة أخرى للنهج المتمحور البيانات هو أنه يفتح الباب لخبراء المجال الذين ليسوا على دراية جيدة بالذكاء الاصطناعي/تعلم الآلة للمساهمة في المشروع. من المحتمل أن يكونوا على دراية بالبيانات، ويمكنهم أن يؤدوا دوراً مركزياً في إعداد عملية تصنيف متينة، وفي إصلاح التصنيفات غير المتسقة، وفي تحديد ”مجالات الخطأ“ للحصول على مزيد من البيانات المصنفة منها. بعد نشر النموذج، يمكنهم المساعدة في مراقبة النموذج لضمان استمرار فاعليته، ويمكنهم جمع بيانات تدريب جديدة لإعادة تدريب النموذج مع تغيُّر البيئة المحيطة. يمكن تبسيط هذه الأنشطة وجعلها فاعلة باستخدام البرامج ذات الأغراض الخاصة، ومهام سير العمل المحسّنة للمستخدمين النهائيين ذوي الألفة مع البيانات الذين ليسوا خبراء في تعلم الآلة.
جلب ممارسة الذكاء الاصطناعي الموفر للبيانات إلى المؤسسة
مسلحين بفهم عالي المستوى للحلول الممكنة، يمكن للمديرين البدءُ في استكشافها مع قادة مشروعات الذكاء الاصطناعي لديهم، مسترشدين بالأسئلة التالية:
■ ما نقطة البداية لتطوير النموذج؟ هل هو نموذج جرى اختباره مسبقاً أو إننا نبني نموذجاً من الصفر؟
■ إذا كان الأمر الأول، فكيف اخترنا النموذج الذي جرى اختباره مسبقاً؟ كيف نعرف أنه مناسب لأنواع بيانات الإدخال في هذا المشروع؟
■ إذا كان الأمر الأخير، فما أسباب عدم البدء بنموذج جرى اختباره مسبقاً؟ هل ينبع ذلك من الطبيعة الفريدة أو الملكية لبيانات الإدخال؟ إذا كان الأمر كذلك فهل حاولنا بناء برنامج التشفير الخاص بنا باستخدام التعلم الخاضع للإشراف الذاتي أو التعلم المتباين؟ وإذا لم يكن كذلك، فلماذا؟
■ ما مصدر التصنيفات في بيانات التدريب والاختبار؟ كيف نكتشف وجود أخطاء في التصنيفات ونخفف من آثارها؟
■ ما إجراءاتُنا لتحليل أخطاء النمذجة وتحديد مجموعة البيانات التالية الأكثر فائدة لجمع التصنيفات؟
■ لاكتشاف أخطاء التصنيف وتحليل خطأ النموذج، هل يكون العمل يدوياً؟ هل هناك فرصة لجعل سير العمل هذا أكثر كفاءة من خلال إدخال أدوات برمجية؟
يمكن لتقنيات الذكاء الاصطناعي الموفرة للبيانات وأفضل الممارسات التي وصفتها أن تساعد كبار القادة الذين يدافعون عن تطوير تطبيقات الذكاء الاصطناعي واستخدامها في مؤسساتهم لكنهم يواجهون تحدي عدم كفاية البيانات المصنفة. من خلال التأكد من أن فِرَق الذكاء الاصطناعي تستكشف الخيارات كلها، يمكن للقادة زيادة احتمال النجاح، وتحسين العائد على الجهد، وتقصير نسبة الوقت إلى القيمة لمشروعات الذكاء الاصطناعي الاستراتيجية الخاصة بهم.
راما راماكريشنان
المراجع
| ↑1 | M. Bernstein, “Labeling and Crowdsourcing,” Data-Centric AI, accessed June 13, 2022, https://datacentricai.org. |
|---|---|
| ↑2 | N. Diamant, E. Reinertsen, S. Song, et al., “Patient Contrastive Learning: A Performant, Expressive, and Practical Approach to Electrocardiogram Modeling,” PLOS Computational Biology 18, no. 2 (Feb. 14, 2022): 1-16. |
| ↑3 | S. Brown, “Why It’s Time for ‘Data-Centric Artificial Intelligence,’ ” MIT Sloan School of Management, June 7, 2022, https://mitsloan.mit.edu. |
| ↑4 | M.D. Zeiler and R. Fergus, “Visualizing and Understanding Convolutional Networks,” in “Computer Vision — ECCV 2014,” eds. D. Fleet, T. Pajdla, B. Schiele, et al. (Zurich: Springer, 2014), 824. |
| ↑5 | A. Kolesnikov, L. Beyer, X. Zhai, et al., “Big Transfer (BiT): General Visual Representation Learning,” arXiv, May 5, 2020, https://arxiv.org. |
| ↑6 | T. Chen, S. Kornblith, M. Norouzi, et al., “A Simple Framework for Contrastive Learning of Visual Representations,” arXiv, Feb. 13, 2020, http://arxiv.org. |
| ↑7 | .Ibid |
| ↑8 | F. Chollet, “Deep Learning With Python,” 2nd ed. (Shelter Island, New York: Manning Publications, 2021). |
| ↑9 | A. Ng, “MLOps: From Model-Centric to Data-Centric AI,” PDF file (Palo Alto, California: DeepLearning.AI, June 2021), www.deeplearning.ai. |
| ↑10, ↑13 | Chollet, “Deep Learning With Python.” |
| ↑11 | DeepLearning.AI, “A Chat With Andrew: MLOps: From Model-Centric to Data-Centric AI,” YouTube video, 1:00:10, March 4, 2021, www.youtube.com. |
| ↑12 | D. Wang, A. Khosla, R. Gargeya, et al., “Deep Learning for Identifying Metastatic Breast Cancer,” arXiv, June 18, 2016, https://arxiv.org. |





